

Un genoma de referencia (o versión de referencia de un genoma) es una base de datos digital de secuencias de ácidos nucleicos, creado por científicos como ejemplo representativo del conjunto de genes de un organismo idealizado de una especie. Al ser resultado de un ensamblado de la secuenciación del ADN a partir de un número determinado de donantes, los genomas de referencia no representan con total exactitud el genoma de un organismo individual. En su lugar, un genoma de referencia representa un mosaico haploide de diferentes secuencias de ADN de cada donante. Por ejemplo, la versión de referencia más reciente para el genoma humano (versión GRCh38/hg38) proviene de >60 bibliotecas genómicas. Existen genomas de referencia para múltiples especies de virus, bacterias, hongos, plantas y animales. Los genomas de referencia sirven como guía a partir de la cual se construyen los nuevos, permitiendo que estos se ensamblen de manera mucho más barata y rápida que en el primer Proyecto Genoma Humano. Es posible acceder a genomas de referencia a través de diferentes buscadores como Ensembl o UCSC Genome Browser.
Propiedades
Medida de la longitud
La longitud de un genoma puede ser medida de múltiples maneras.
Una manera sencilla de medir la longitud de un genoma es contar el número de pares de bases.
Se denomina golden path a una medida de longitud alternativa que omite las regiones redundantes, tales como los haplotipos y las regiones pseudoautosómicas. Se suele combinar toda la información del ensamblado del genoma al superponer la información de la secuenciación sobre un mapa físico del genoma. Esta unidad de medida supone una mejor estimación del aspecto real del genoma, incluyendo los huecos redundantes y siendo un mapa más extenso que el típico ensamblado.
Cóntigos y scaffolds

El ensamblado de un genoma de referencia requiere el solapamiento de las lecturas, las cuales se alinean formando cóntigos, regiones contiguas de secuencias consenso. Si existen huecos entre cóntigos, estos pueden ser completados creando scaffolds (en inglés, andamios), mediante una amplificación de los cóntigos por PCR y posterior secuenciación o mediante clonación de cromosomas artificiales bacterianos (BAC). Sin embargo, esto no siempre es posible, existiendo múltiples scaffolds en un genoma de referencia. Los scaffolds se pueden clasificar en tres tipos: 1) Posicionados, de los cuales se conoce el cromosoma en el que se encuentran, coordenadas dentro de este y orientación; 2) No localizados, de los que solo se conoce el cromosoma, pero no las coordenadas ni la orientación; 3) No posicionados, cuyo cromosoma tampoco se conoce.
El número de cóntigos y de scaffolds, así como sus longitudes medias son parámetros relevantes, junto con muchos otros parámetros, para la evaluación de la calidad de un genoma de referencia ya que informan sobre la continuidad del mapeado final a partir del genoma original. Cuanto menor sea el número de scaffolds por cromosoma hasta que uno solo ocupe un cromosoma entero, mayor será la continuidad del ensamblado. Otros parámetros relacionados son N50 y L50. El primero se define como la longitud de los cóntigos/scaffolds en la que el 50% del ensamblado se encuentra en fragmentos de esta longitud o mayor, mientras que el segundo es el número de cóntigo/scaffold cuya longitud es N50. Cuanto mayor sea el valor de N50, menor será el de L50, y viceversa, informando de una alta continuidad en el ensamblado.
Genomas de mamíferos
Los genomas de referencia humanos y murinos son continuamente mejorados por el Consorcio de Referencia del Genoma (GRC), un grupo de 20 investigadores de diferentes institutos de investigación, incluyendo el Instituto Europeo de Bioinformática, el NCBI, el Sanger Institute y el McDonnell Genome Institute de la Universidad de Washington en San Luis (EE.UU.). El GRC continua mejorando los genomas de referencia, reduciendo los huecos y las regiones infrarrepresentadas en la secuencia de los genomas de referencia.
Genoma de referencia humano
El primer genoma de referencia humano se extrajo de 13 voluntarios anónimos de Búfalo, Nueva York, los cuales fueron reclutados el domingo 23 de marzo de 1997. Se invitó a los primeros diez hombres y mujeres voluntarios a una reunión con los consejeros genéticos del proyecto para la posterior extracción de sangre. Debido a la metodología de procesamiento de las muestras de ADN, aproximadamente el 80% del genoma de referencia provenía de 8 personas y un hombre, designado como RP11, que contribuyó con el 66% del total. El sistema de grupos sanguíneos ABO difieren entre humanos, pero el genoma de referencia humano solo contiene el alelo O, aunque los otros están anotados. En 1999, se logró secuenciar y ensamblar la secuencia del cromosoma 22 y en 2001, se publicaron los resultados iniciales del primer ensamblado de referencia para el genoma humano.

Conforme el coste de las tecnología de secuenciación del ADN ha descendido y han surgido otras nuevas para la secuenciación de genoma completo, el número de genomas secuenciado ha aumentado. En muchos casos, personas como James D. Watson, secuenciaron su genoma mediante el método de secuenciación masiva en paralelo (massive parallel sequencing, en inglés). La comparativa entre la versión de referencia (versión NCBI36/hg18) y el genoma de Watson reveló diferencias en 3,3 millones de polimorfismos de un nucleótido único, mientras que aproximadamente el 1,4 % de su ADN no se podía alinear contra ninguna región del genoma de referencia. En las regiones de un genoma donde se sabe que existe variabilidad a gran escala en la secuencia, una serie de loci alternativos se ensamblan a lo largo del locus de referencia.
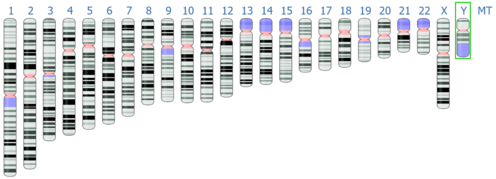
La última versión del genoma de referencia humano, publicada por el Consorcio de Referencia del Genoma, fue GRCh38 en 2017. Esta versión ha recibido varios parches para actualizarla, siendo el último parche GRCh38.p14, publicada en marzo de 2022. Esta solo contiene 349 huecos en todo el genoma, lo que supuso un avance importante respecto a la primera versión, la cual tenía aproximadamente 150 000 huecos. Esta versión presenta huecos principalmente en regiones correspondientes a telómeros, centrómeros y secuencias largas y repetitivas, estando el mayor hueco situado a lo largo del brazo largo del cromosoma Y, una región de aproximadamente 30 Mb de longitud (~52% de la longitud total del cromosoma Y).
El número de bibliotecas genómicas que contribuyen al genoma de referencia ha aumentado de manera constante a lo largo de los años hasta más de 60. Sin embargo, el individuo RP11 sigue suponiendo el 70% del genoma de referencia. Los análisis genómicos de este hombre anónimo sugieren que es de ascendencia afroeuropea. En 2022, el Consorcio Telomere-to-Telomere (T2T) publicó la primera versión del genoma humano totalmente completo (versión T2T-CHM13), sin huecos en el ensamblado de las secuencias. Por otra parte, según el sitio web oficial del GRC, el lanzamiento de la siguiente versión del genoma de referencia humano (versión GRCh39) se encuentra actualmente "indefinidamente pospuesto".
Recientes versiones del genoma de referencia humano:
| Versión | Fecha de publicación | Versión equivalente de UCSC |
|---|---|---|
| GRCh39 | Pospuesto indefinidamente | - |
| T2T-CHM13 | Enero 2022 | - |
| GRCh38 | Diciembre 2013 | hg38 |
| GRCh37 | Febrero 2009 | hg19 |
| NCBI36.1 | Marzo 2006 | hg18 |
| NCBI35 | Mayo 2004 | hg17 |
| NCBI34 | Julio 2003 | hg16 |
Limitaciones
La versión de referencia proporciona una buena aproximación a una gran parte del genoma de un individuo. Sin embargo, en regiones con una alta diversidad alélica, como en el caso del Complejo Mayor de Histocompatibilidad (CMH) en los humanos o las proteínas urinarias mayores de los ratones, el genoma de referencia puede diferir significativamente entre diferentes individuos. Debido al hecho de que el genoma de referencia se trata de una sola secuencia de ADN, lo cual le aporta su utilidad como índice o marcador de las características genómicas, esto implica limitaciones en términos de en qué grado representa fielmente el genoma humano y su variabilidad. Por otra parte, la mayoría de las muestras obtenidas para la secuenciación del genoma de referencia pertenecen a individuos de ascendencia europea, siendo estas poblaciones las mejor caracterizadas y estudiadas en detrimento de poblaciones no europeas. En 2010, se comprobó, mediante un ensamblado de novo de genomas extraídos de poblaciones africanas y asiáticas con el genoma de referencia del NCBI (versión NCBI36.3), que estos genomas tenían aproximadamente 5 Mb de secuencias que no alineaban contra ninguna región del genoma de referencia.
Proyectos posteriores al Proyecto Genoma Humano buscan abordar una caracterización más profunda y diversa de la variabilidad genética humana, que el genoma de referencia no es capaz de representar. El Proyecto HapMap, en activo durante el periodo 2002 - 2010, con el propósito de crear un mapa de haplotipos y sus variaciones más comunes entre diferentes poblaciones humanas. Se estudiaron hasta 11 poblaciones de diferente ascendencia, por ejemplo, individuos de etnia Han de China, guyaratís de la India, del pueblo yoruba de Nigeria o japoneses, entre otros. El Proyecto 1000 Genomas, llevado a cabo en el periodo 2008 - 2015, con el objetivo de crear una base de datos que comprenda más del 95 % de las variaciones presentes en el genoma humano y cuyos resultados puedan ser utilizados en estudios de asociación con enfermedades (GWAS) como diabetes, enfermedades cardiovasculares o autoinmunes. Un total de 26 grupos étnicos diferentes fueron estudiados en este proyecto, ampliando el alcance del proyecto HapMap a nuevos grupos étnicos como el pueblo mendé de Sierra Leona, el pueblo vietnamita o el pueblo bengalí. El Proyecto del Pangenoma Humano, el cual entró en su fase inicial en 2019 con la creación del Consorcio de Referencia del Pangenoma Humano, busca crear el mayor mapa de la variabilidad genética humana, tomando como punto de partida los resultados ya obtenidos en proyectos anteriores.
Genoma de referencia murino
Recientes versiones del genoma de referencia de ratón:
| Versión | Fecha de publicación | Equivalente versión UCSC |
|---|---|---|
| GRCm39 | Junio 2020 | mm39 |
| GRCm38 | Diciembre 2011 | mm10 |
| NCBI37 | Julio 2007 | mm9 |
| NCBI36 | Febrero 2006 | mm8 |
| NCBI35 | Agosto 2005 | mm7 |
| NCBI34 | Marzo 2005 | mm6 |
Otros genomas
Desde la finalización del Proyecto Genoma Humano, han surgido múltiples proyectos a escala internacional centrados en generar genomas de referencia para multitud de organismos, tanto organismos modelo (ej.: pez cebra (Danio rerio), pollo (Gallus gallus), Escherichia coli etc.) como otros organismos de interés para la comunidad científica, por ejemplo, especies en peligro de extinción (ej.: arowana asiática (Scleropages formosus) o el bisonte americano (Bison bison)). A fecha de agosto de 2022, de acuerdo con la base de datos del NCBI, hay registrados 71 886 genomas parcial o completa secuenciados y ensamblados de diferentes especies, entre los que se encuentran 676 mamíferos, 590 aves y 865 peces. También son destacables las cifras de 1796 genomas de insectos, 3747 hongos, 1025 plantas, 33 724 bacterias, 26 004 virus y 2040 arqueas. Muchas de estas especies tienen anotación genómica asociada a sus genomas de referencia, que puede ser consultada y visualizada públicamente en navegadores genómicos como los de Ensembl y el UCSC Genome Browser.
Algunos ejemplos de estos proyectos son: el Proyecto Genoma del Chimpancé, llevado a cabo en el periodo 2005 - 2013 conjuntamente por el Instituto Broad el Instituto del Genoma McDonnell de la Universidad de Washington en San Luis y que generó los primeros genomas de referencia para 4 subespecies de Pan troglodytes; el Proyecto 100K Genomas de Patógenos, iniciado en 2012 con el objetivo de generar una base de datos de genomas de referencia para 100 000 microorganismos patógenos para su uso en la salud pública, detección de brotes infecciosos, agricultura y medioambiente; el Proyecto Earth BioGenome, iniciado en 2018 y que pretende secuenciar y catalogar los genomas de todos los organismos eucariotas de la Tierra para promover proyectos de conservación de la biodiversidad, en conjunto con 50 proyectos afiliados de menor escala como el Proyecto Africa BioGenome o el Proyecto 1000 Genomas de hongos.
| Control de autoridades |
|
|---|
-
 Datos: Q7307127
Datos: Q7307127
-
 Multimedia: Reference genome / Q7307127
Multimedia: Reference genome / Q7307127